
一个基于Qwen2.5-Coder-3B的小模子,靠后检修在AIME26、LiveCodeBenchv6等可考据任务上冲到前沿模子隔壁。
3B参数,原本应该是小模子的舒畅区。
能土产货跑,资本低,速率快,合适作念轻量任务。很少有东说念主会把它和ClaudeOpus4.5、DeepSeekV3.2、KimiK2.5、GLM-5、Gemini3Pro这么的前沿模子作念对比。
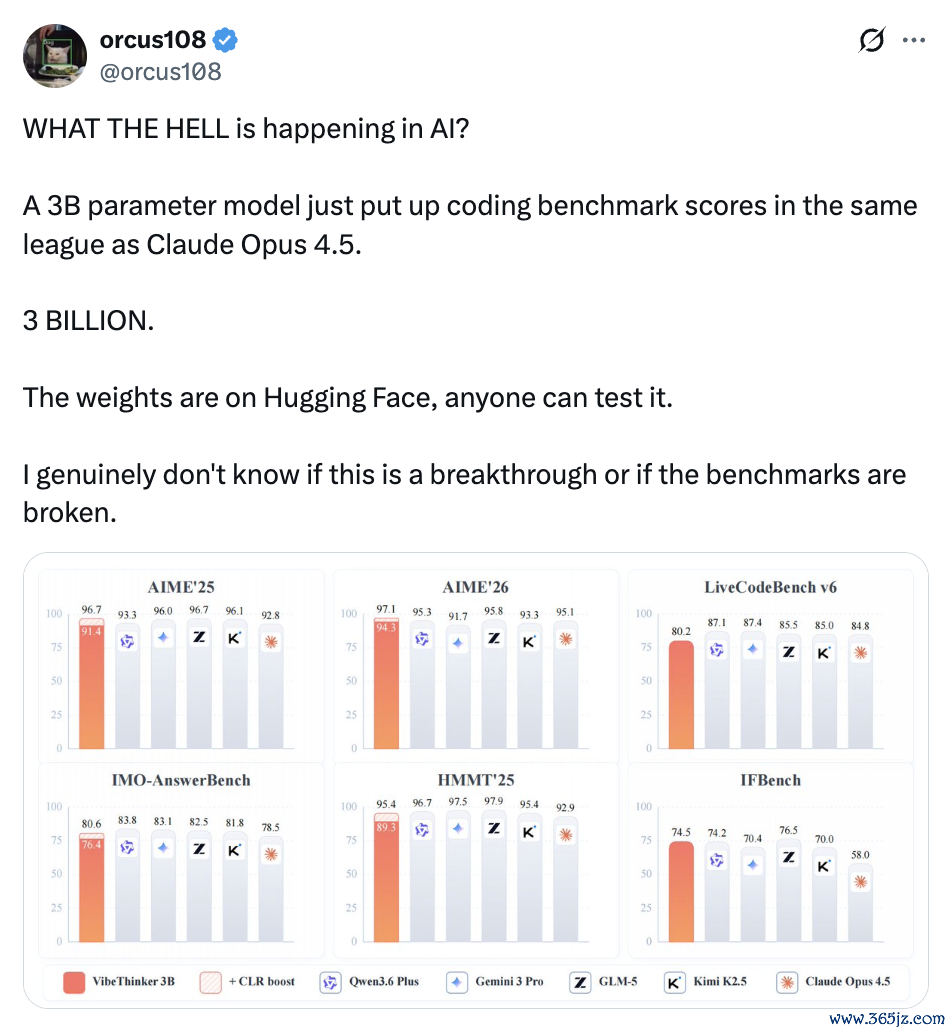
VibeThinker-3B此次偏巧挤了进来。
代码部分先把争议拉满了,LiveCodeBenchv6上,VibeThinker-3B拿到80.2,距离ClaudeOpus4.5的84.8一经不远。
AIME26上,它又拿到94.3,以0.1分的隐微上风险胜671B参数的DeepSeekV3.2(94.2)。加入声明级可靠性评估(CLR)后,得益升到97.1。模子权重也已公开。
VibeThinker-3B的签订围聚在数学、代码和部分STEM这类考据信号明确的任务上。在这些任务上,它至少证实,小模子的可考据推理上限可能比许多东说念主预期得更高。

论文标题:
VibeThinker-3B:ExploringtheFrontierofVerifiableReasoninginSmallLanguageModels
论文承接:
2026世界杯在线买输赢平台代码承接:
https://github.com/WeiboAI/VibeThinker

参数后果
参数反差在IMO-AnswerBench上最直不雅。VibeThinker-3B通例得益为76.4,加入CLR后达到80.6。
行为参照,DeepSeekV3.2为671B,得分78.3;GLM-5为744B,得分82.5;KimiK2.5为1T,得分81.8。
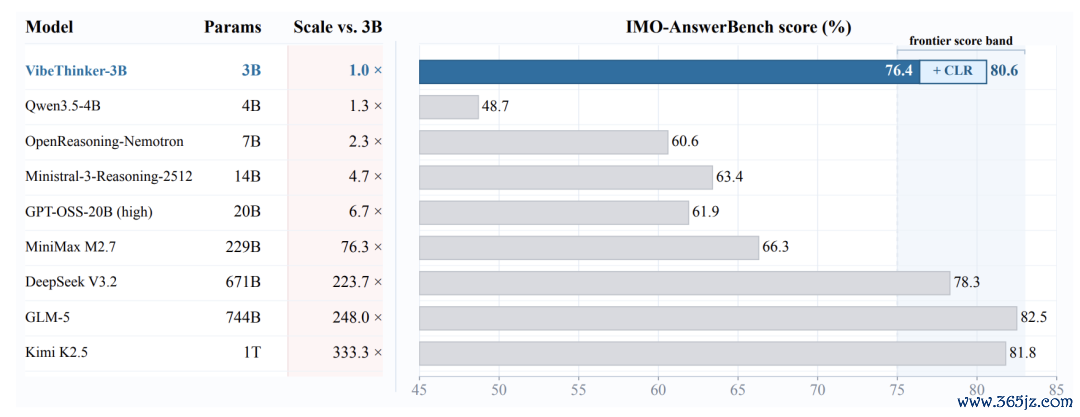
〓VibeThinker-3B在IMO-AnswerBench上展现出凸起的参数后果。
单看这个基准,3B参数一经参预数百B到1T模子的得分区间。
VibeThinker-3B在AIME26上为94.3,LiveCodeBenchv6为80.2,IFEval为93.4;加入CLR后,AIME26、HMMT25、BruMO25和IMO-AnswerBench区分升至97.1、95.4、99.2和80.6。
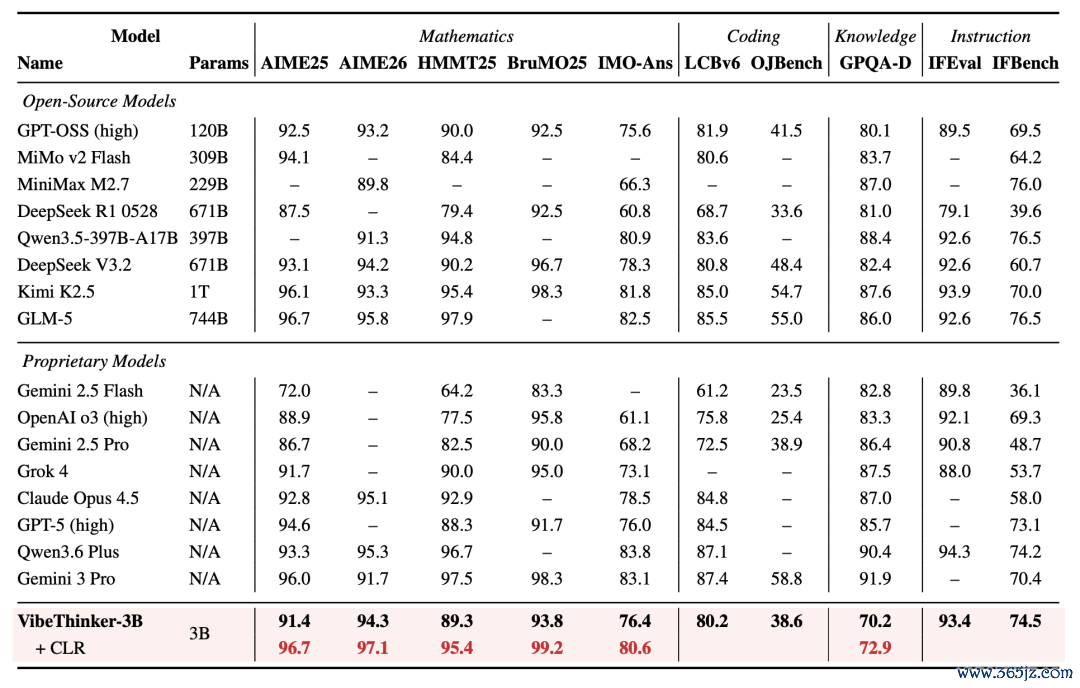
〓VibeThinker-3B与前沿推理模子的中枢方针对比。

后检修路子
外部议论最原谅的,是VibeThinker-3B如安在旧底座上络续作念后检修。

它使用的底座是Qwen2.5-Coder-3Bbase,枢纽在于怎么通过数据构造、SFT、强化学习和自蒸馏,继续开释3B模子的推理才调。
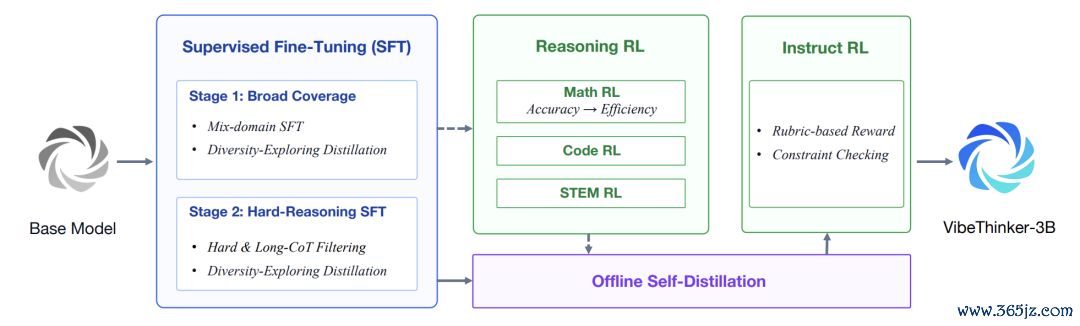
〓VibeThinker-3B的检修经过由两阶段SFT、多域强化学习、离线自蒸馏和教导强化学习构成。
SFT阶段遴选两阶段课程学习。
前一阶段作念广域覆没,数据包括数学、代码、STEM推理、通用对话和教导扈从。
后一阶段转向高难长程推理样本,亚搏体育中国官方网站入口过滤掉推理轨迹短于5Ktoken的样本,并用VibeThinker-1.5B对每个问题作念8次落寞采样,去掉失实率低于0.75的相对马虎题。
数据构造相通是这套检修栈的枢纽。其中,各样性探索蒸馏发扬保留多种灵验解法,而非沿单一齐径作念效法。
模子通过多旅途推理蒸馏学习不同认识神气、推导旅途和考据计策,再经过n-gram过滤、查询质地过滤、谜底考据、代码沙箱实际和多数投票,缩短低质地样本与基准浑浊风险。
中间checkpoint的遴荐也更偏向各样性:团队在领域探伤集上看Pass@K,挑出能产生更多灵验解的领域人人模子,再作念参数级吞并。
强化学习阶段沿用MGPO。对每个问题,模子会采样一组回答,并用警戒正确率(p(q))算计它对现时模子的难度。正确率接近0.5的样本最有价值,因为它们正处在模子会与不会之间,MGPO会给这类样本更高权重。
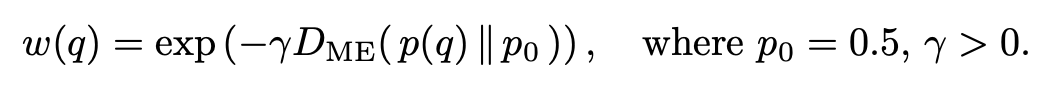
这么一来,kaiyun官方网站强化学习更新会更围聚地放大鸿沟样本中的可考据信号。
检修规定是数学强化学习、代码强化学习、STEM强化学习。VibeThinker-3B径直遴选64K长高下文强化学习,减少早期采样轨迹截断对长推理行径的絮叨。
随后是Long2ShortMathRL。模子先优化准确率,再通过中心化长度感知奖励偏移,在正确轨迹里面按长度从头分拨奖励。
更短的正确谜底赢得更高奖励,较长的正确谜底奖励缩短,同期保持组内奖励偏移总数为零。标的是保住正确率,同期减少冗余推理。
离线自蒸馏还引入了学习后劲筛选。团队先用领域考据器过滤失实轨迹,再用学习后劲得分揣度每条正确轨迹的蒸馏价值。
该得分来自学生模子对轨迹的长度归一化负对数似然;分数越高,证实学生越莫得充分掌合手这条正确轨迹,蒸馏价值也越高。
终末的教导强化学习则面向口头、规定、数目、枢纽词拘谨和任务完成度,普及复杂教导下的可控性。

可考据推理
工夫证明用参数压缩-覆没假说解释了这一气候。
数学、代码和部分STEM任务有明确响应,中枢挑战在于搜索、拘谨振作、失实修正和多步组合。证明觉得,这类才调更容易压缩进一个小而可复用的推理中枢。
绽放域学问则更像覆没问题,需要模子记着大齐事实、宗旨、语义关联和长尾场景。VibeThinker-3B能在AIME、LiveCodeBench、IMO-AnswerBench上接近前沿模子,却无法全面追平通用大模子,原因也在这里。
CLR进一步放大了谜底可判定任务的上风。它不更新模子参数,而是在测试时生成32条候选轨迹;每条轨迹齐会索要最终谜底和5个有策画关系声明,再由模子自行考据这些声明。
枢纽声明一朝出错,轨迹可靠性会被非线性压低。候选谜底按等价关系聚类后,再累加同组轨迹的可靠性分数,选出最终谜底。
AIME26从94.3到97.1,靠的是测试时彭胀带来的增益。分数提高了,推理资本也会增多,不行和闲居单次推理得益混在一齐相比。

才调鸿沟
VibeThinker-3B更接近一个可考据推理模子,而不是通用旗舰模子的替代品。
GPQA-Diamond更能证实它的鸿沟。VibeThinker-3B通例得益为70.2,加入CLR后为72.9,仍然过时于最强的旗舰模子。
这个差距证实,3B参数不错承载很强的推理要津,但学问密集型任务依然练习参数覆没。
近期LeetCode周赛、双周赛测试,在一定进程上回答了静态基准过拟合的疑虑。在仅用Python的单次生成评测中,8场近期比赛共128次初次提交,VibeThinker-3B通过123次,举座通过率96.1%。
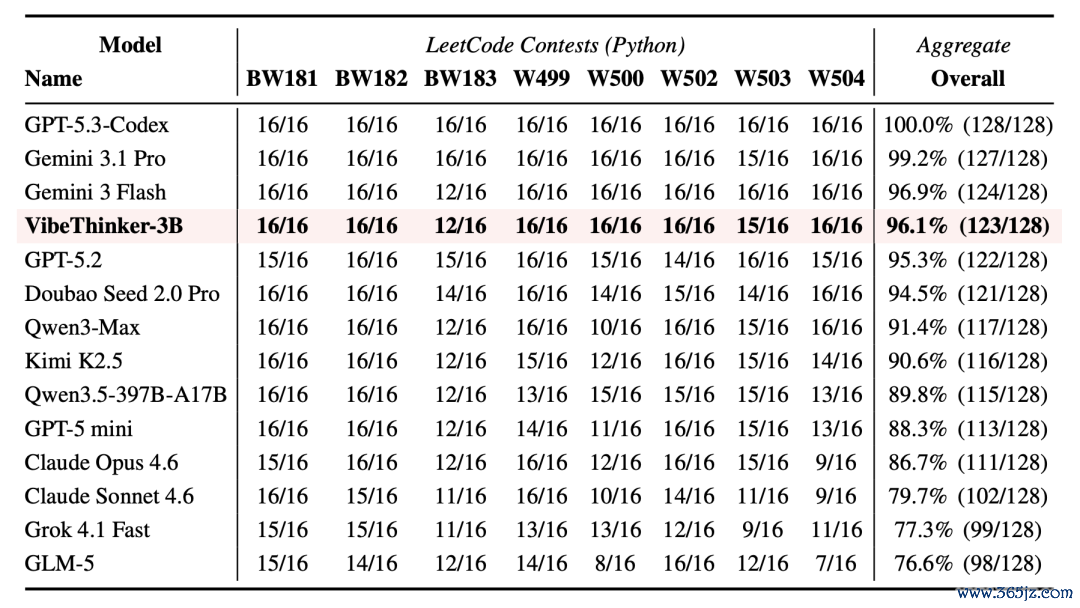
〓VibeThinker-3B在近期LeetCode比赛中的代码泛化测试。
这证实,它的代码才调不单体面前静态基准上。不外,这类题型仍然可实际、可自动评测、鸿沟了了,距离通用编程智能体或绽放式软件工程还有显豁远隔。
VibeThinker-3B莫得证明3B模子不错替代通用旗舰模子。更准确地说,在谜底可判定、检修信号可靠、后检修裕如精采的任务上,小模子的上限正在被从头评估。
大模子仍然承担学问覆没和通用才调的主要变装。但在参数限度除外,高质地数据、可考据响应、长推理检修和测试时彭胀kaiyun(中国)体育,一经足以把小模子推到更高的才调区间。